This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
Throughout the web’s history, static websites have always been a popular option due to their simplicity, scalability, and security. In the 2000s we had a showdown of two popular blog publishing platforms — MovableType in 2001 and WordPress in 2003. Aug 31 & Sep 1, 2021. Jump to the workshop ?.
Werner Vogels weblog on building scalable and robust distributed systems. 2003: Linkin Park, Meteora. All Things Distributed. An Album for Each Year - 2012 Version. By Werner Vogels on 22 December 2012 06:00 PM. Comments (). About 5 years ago I joined a challenge to list "a favorite album for every year of your life."
The term site reliability engineering first came into existence at Google in 2003 when a site reliability team was created. He was asked in 2003 to create and manage a team of seven engineers which eventually led him to create the new role/title. At that time, the team was made up of software engineers.
On the other hand if testing MySQL or MariaDB for the ability to handle a more complex workload such as the use of stored procedures and in particular if looking to compare scalability with a traditional database then HammerDB is focused more towards testing those enterprise features. Copyright (C) 2003-2018 Steve Shaw. dbset db mysql.
We argue that RInK stores should not be used when implementing scalable data center services. Yes, a bit like those 2nd-level caches we were talking about earlier, e.g. Ehcache from 2003 onwards. A rule that hard and fast seems just as likely to be wrong as a strict interpretation of factor six from the 12-factor app guidelines is.
WordPress is one of the most popular and obvious choices for businesses that are looking out to run and manage a robust, scalable, and effective platform that can change as per their business needs irrespective of any hindrances. Details founded: 2003 employees: 200-250 hourly rates: $25- $49 clutch rating: 4.6
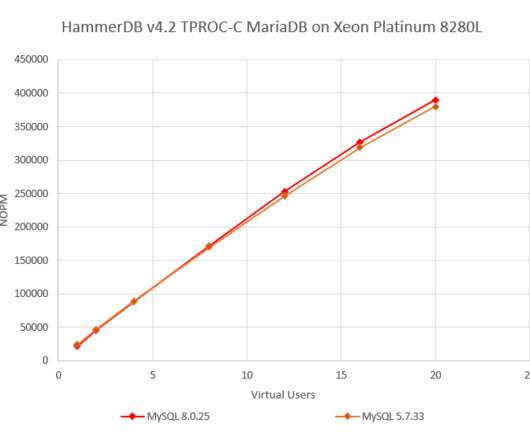
One of the most important concepts in analysing database performance is that of understanding scalability. Plotting these data points enables us to understand the scalability of the database software being tested on that system. In particular, this means as we add CPU cores and increase the system load, we see higher performance.
Copyright (C) 2003-2018 Steve Shaw. Then add the library to the library path: postgres:~$ export LD_LIBRARY_PATH=/usr/local/pgsql/lib:$LD_LIBRARY_PATH. and check that it loads with a librarycheck test. $./hammerdbcli. hammerdbcli. HammerDB CLI v3.1. Type "help" for a list of commands. The xml is well-formed, applying configuration.
I presented a keynote for Sun at Supercomputing 2003 in Phoenix Arizona and included the slide shown below. CXL is a memory protocol, as shown in the third block in my diagram from 2003, and provides cache coherent latency around 200ns, and up to 2 meters maximum distance.
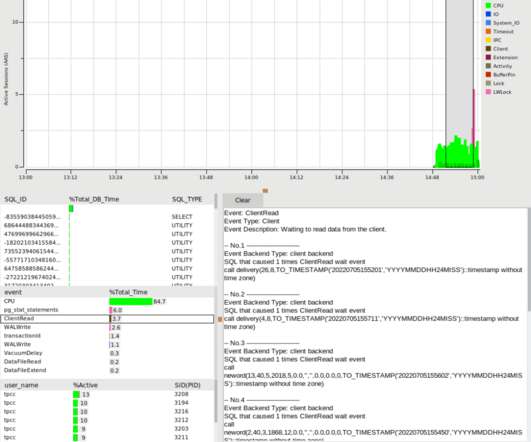
Also note that with the Tcl workload we now start to see some of the LWLock wait events that a database engineer working on scalability would focus on and we can use the HammerDB PostgreSQL statistics viewer to drill down on some of these wait events. hammerdbcli auto pgtime.tcl HammerDB CLI v4.4
Build a more scalable, composable, and functional architecture for interconnecting systems and applications. In 2003, Gregor Hohpe and Bobby Woolf released their book Enterprise Integration Patterns. In this article, we will discuss the need for—and how to achieve—modernization in the field of enterprise integration.
This article Threads Done Right… With Tcl gives an excellent overview of these capabilities and it should be clear that to build a scalable benchmarking tool this thread performance and scalability is key. You can download and compile TCL/TK 8.6 HammerDB CLI v3.1 loaded library redis for Redis hammerdb> Database Extensions.
Breakaway opportunities tend also to be highly sensitive to non-functional requirements, such as performance, scalability and security. See also, “Reduce IT Risk for Business Results,” Gartner Research, 14 October 2003 2 The seminal work in this area is Waltzing with Bears by Tom DeMarco and Tim Lister.
To a certain extent, such a high diversity of recommendation techniques is attributed to several implementation challenges like a sparsity of customer ratings, computational scalability, and lack of information on new items and customers. Prairie, 2003. PZ07] Content-based Recommendation Systems, M. Pazzani, D. Billsus, 2007.
Werner Vogels weblog on building scalable and robust distributed systems. Jul 20 - Disco: Running Commodity Operating Systems on Scalable Multiprocessors by Edouard Bugnion, Scott Devine, Kinshuk Govil, Mendel Rosenblum in the Proceedings of the 16th ACM Symposium on Operating Systems Principles, October 5-8, 1997, St. Comments ().
Werner Vogels weblog on building scalable and robust distributed systems. Disco: Running Commodity Operating Systems on Scalable Multiprocessors by Edouard Bugnion, Scott Devine, Kinshuk Govil, Mendel Rosenblum in the Proceedings of the 16th ACM Symposium on Operating Systems Principles, October 5-8, 1997, St. All Things Distributed.
Here’s the real news though: there’s a full-on scalable API now. It’s just now it’s not a side project anymore, it’s got the support of a company dead-focused on helping developers. Linux; Android 6.0.1; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Mobile Safari/537.36 Mobile Safari/537.36
I became the Sun UK local specialist in performance and hardware, and as Sun transitioned from a desktop workstation company to sell high end multiprocessor servers I was helping customers find and fix scalability problems. I also applied Six Sigma to capacity planning and presented this at a conference in 2003.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content